Introducing KendraCyber’s Resilience Playbook: An Eight-Part Blog Series for SaaS Leaders
Cloud adoption has never been higher, yet 2024–2025 produced a record number of multi-hour outages across every major hyperscaler. A single Identity-as-a-Service hiccup locked thousands of employees out of their tools; a regional network event sent latency through the roof for a dozen high-growth platforms. In every post-incident review, two patterns surfaced:
- Fail-over was available—but not truly resilient.
- Dependencies outside the engineering team’s direct control amplified the blast radius.
At Kendracyber we’ve helped several SaaS providers uncover these blind spots, architect defensible disaster‑recovery (DR) patterns and, crucially, embed a “resilience mindset” across product, operations and leadership. The conversations are always eye‑opening, so we decided to capture the most valuable lessons in an eight‑part blog series.
Below is your roadmap to what we will publish over the coming weeks, why we chose these topics and—most importantly—why they will be worth your time.
Why another DR series?
Plenty of excellent whitepapers explain availability zones (AZs), multi-region data stores, or AWS-native backup services. Fewer connect those technical building blocks with business realities:
- Vendor lock-out: What happens if your single sign-on provider is down but your compute layer is fine?
- Compliance exposure: Can you prove to auditors that your secondary region meets the same encryption and monitoring baselines?
- Cultural readiness: Does every engineer know who pulls the fail-over trigger at 2 a.m. on a Sunday?
The eight-post arc
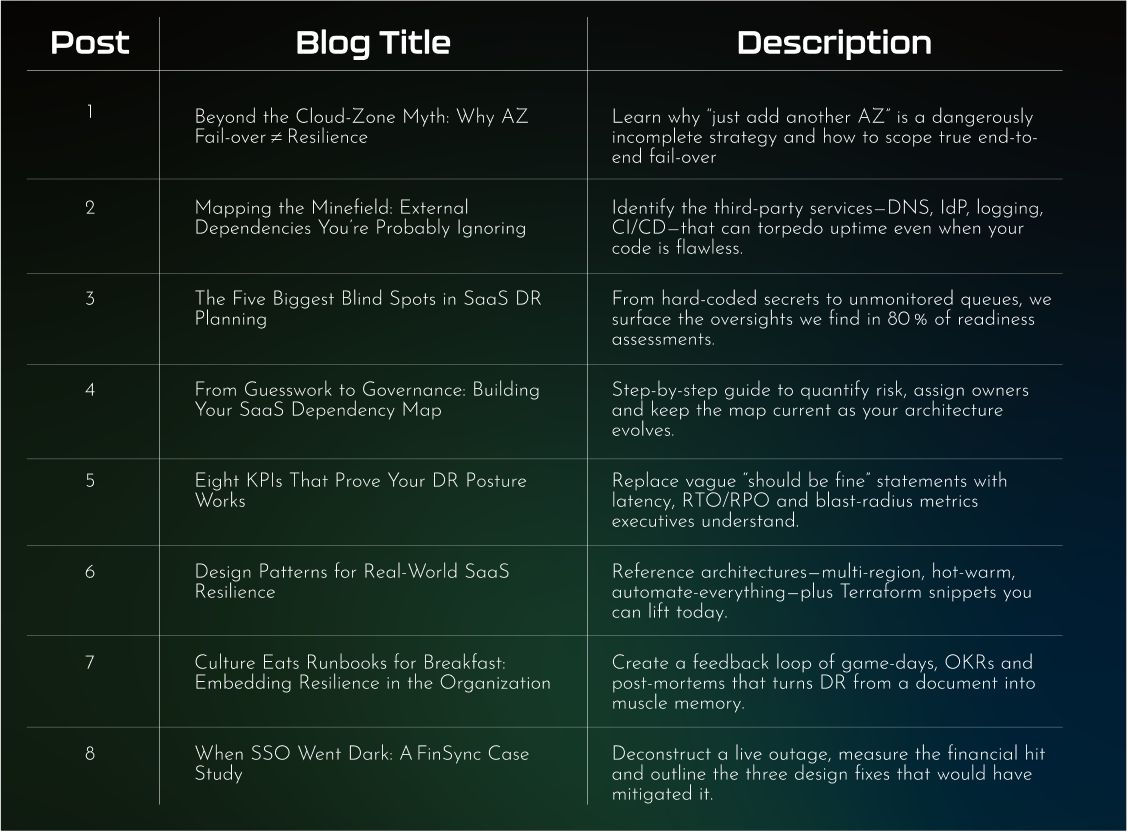
How we selected the topics
Data-driven pain points. We mined five years of Kendracyber assessment notes, incident retrospectives and board briefings. The same questions appeared across seed-stage disruptors and public-market leaders: “Is multi-AZ enough?”, “Who owns our vendor map?”, “What metrics convince investors we’re covered?” Each blog answers one of those recurring queries.
Progressive skill-building. The series starts by challenging common assumptions, moves into tactical mapping and engineering patterns, then zooms out to culture and real-world consequences. You can jump into any post, but reading in order gives a structured maturity path.
Action over theory. Every article ends with a “Next 5 days” checklist. We believe readers should leave with a tangible improvement they can demo at the next stand-up, whether that’s a Config rule, a revised SLA clause or a scheduled gameday.
Why these posts will be worth your time
- Holistic view, vendor-neutral guidance. We love AWS primitives but also assess Azure, GCP, and specialty providers. Recommendations focus on principles you can implement anywhere.
- Evidence over opinion. Expect outage timelines, KPI dashboards and code snippets, not just platitudes. Where possible we link to public RCA documents and open-source tooling.
- Alignment with auditors. ISO 27017, 27017, 22301 and SOC 2 CC-series controls, and upcoming DORA requirements influence every blueprint. Share the posts with compliance and they’ll thank you.
- Bite-size reading. Each entry lands in the 6- to 8-minute range. We know your backlog is full; learning shouldn’t feel like another project.
Who should follow along?
- CTOs & VP Engineering looking to justify DR budget with clear metrics.
- SRE / DevOps practitioners charged with turning “resilience” into Terraform modules and pipelines.
- Security & compliance leaders preparing for ISO 27017 or DORA audits.
- Product managers who must translate downtime risk into roadmap priority.
- Investors & board members needing a quick litmus test of portfolio resilience
What happens after the series?
Great question. Resilience is a moving target; regulations evolve, architectures pivot and threat actors get creative. We intend the series as a living foundation. After post #8, expect quarterly “state of resilience” updates and community‑driven deep dives—think “Serverless DR patterns” or “AI/ML pipeline roll‑backs.”
Join us on the journey
Resilience isn’t a checklist; it’s a culture of anticipating failure and designing gracefully through it. Whether you’re just adding your second availability zone or fine-tuning multi-region chaos tests, this blog series will meet you where you are—then challenge you to level up.
First installment drops soon. Follow our LinkedIn page and bring your hardest DR challenges; we’ll bring field data, pragmatic tooling and a dash of irreverent humor.
See you beyond the cloud-zone myth.